|
|
Sistema de gestión de tareas SLURM
¿Qué es un administrador de carga de trabajo?
Los clusters del CECC son un recurso finito que comparten muchos usuarios. En la ejecucion de un trabajo los usuarios compiten por los nodos, núcleos, memoria, red, etc. de un clúster y, para utilizar un clúster de manera justa y eficiente se emplea un sistema de software que administrar cómo se realiza el trabajo: Comúnmente se conocen como administrador de carga de trabajo. Un administrador de cargas de trabajo tambien se le denomina Sistema por lotes, programador de lotes, programador de cargas de trabajo, programador de trabajos y administrador de recursos; aunque esta ultima tambien sea considera un componente que hace parte del administrador de carga de trabajo. Dentro de las tareas realizadas por un administrador de carga de trabajo se cuentan- Proporcionar un entorno para que los usuarios especifiquen y envíen sus procesos como "trabajos".
- Evalúa, prioriza, programa y ejecuta trabajos.
- Proporcionar un entorno para que los usuarios controlen, modifiquen e interactúen con los trabajos.
- Administra, asigna y proporciona acceso a los recursos de la máquinas disponibles.
- Administrar los trabajos pendientes en las cola(queue) de trabajos.
- Supervisar y solucionar problemas de trabajos y recursos de la máquina.
- Proporcionar funciones de contabilidad y generación de informes para los trabajos y recursos de las máquinas.
- Equilibra eficientemente el trabajo sobre los recursos de la máquina; minimizar los recursos no usados.
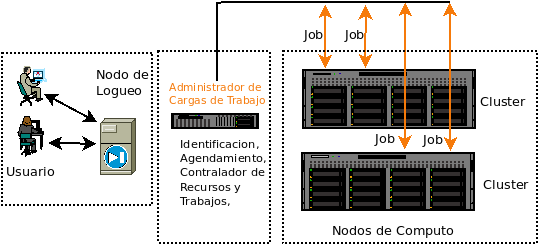 Las funciones generales en las tres etapas demarcadas como Usuario, El Administrador de Cargas de Trabajo y el Cluster se resumen en la tabla:
Las funciones generales en las tres etapas demarcadas como Usuario, El Administrador de Cargas de Trabajo y el Cluster se resumen en la tabla:
| Usuario | Administrador de Cargas de Trabajo | Nodos de Computo |
|
|
|
Conceptos Basicos
Job(s), Trabajo(s)
Para un usuario, un "trabajo" puede definirse como una solicitud destinada a reservar los recursos informáticos necesarios para realizar un proceso informático durante un limite de tiempo. Los trabajos especifican qué recursos se necesitan; como, el tipo de nodo o maquina, la cantidad de nodos, la duración del trabajo, la cantidad de memoria requerida, la cuenta a usar, etc. Los trabajos se envían a SLURM usando un script de trabajo. Un trabajo se caracteriza principalmente por:- Los Recursos Consumibles. Se considera un recurso cualquier "objeto" que pueda ser utilizado (es decir, consumido y, por lo tanto, no disponible para otro trabajo) por un trabajo o dedicado a él . Ejemplos comunes de recursos son la memoria física, las CPU o el disco de almacenamiento local de un nodo. Los adaptadores de red, si son dedicados, también pueden considerarse un recurso consumible.
- Los Recursos y restricciones del Trabajo. Son el conjunto de condiciones que deben cumplirse para que el trabajo comience. Por ejemplo: Tipo de nodo o máquina, el número de procesadores, la velocidad del procesador, la particion o grupo de maquinas donde estan los nodos que ejecutaran el proceso. Caracteriticas , como disco, memoria, GPU, Cuando puede comenzar a procesar el trabajo o si debe comenzar el trabajo con relación a un evento en particular (es decir, comenzar después de que el trabajo X se complete con éxito).
- Entorno o Ambiente de ejecución. una descripción del entorno en el que se inicia el ejecutable, puede incluir atributos como un ejecutable, argumentos de línea de comando, ficheros(archivos) de entrada, archivo de salida, ID de usuario local, ID de grupo local , Limites en los recuirsos del proceso
- Identidad o Credenciales del Usuario. El administrador de cargas de trabajo SLURM, establecen las politicas con las credenciales del usuario. Una vez enviados, los trabajos son asociados al ID par plicar varios tipos de acceso y politicas, por ejemplo niveles de prestacion del servicio(QoS) o una cuenta creada para reportar metricas de uso.
Colas y límites de cola
Los nodos(maquinas) de computo se agrupan en Colas, Pools y/o Particiones en funcion de como deben usarse. Hay limites definidos para cada cola:- Número máximo/mínimo de nodos permitidos para un trabajo.
- Tiempo máximo de reloj de pared: cuánto tiempo se permite ejecutar un trabajo.
- Número máximo de trabajos simultaneos en ejecución o número máximo de nodos permitidos en todos los trabajos en ejecución.
En la Tabla que sigue, una administración Federada sobre los recursos computacionales permite que los usuarios locales de un cluster definan y usen quotas particulares(color verde). Los recursos de cada cluster asociado son compartidos entre todos los usuarios con quotas definidas(color rosa). Cuando en uno de los clusters los usuarios compite por la asignacion de los mismos recursos, una Alta prioridad permite apropiarse(secuestrar) y usar de los recursos mientras, coloca en estado de espera los trabajos en ejecucion de tienen baja prioridad; la ejecución continuará automáticamente cuando los recursos en el cluster esten nuevamente disponibles. Adicionalmente los usuario de un cluster pueden solictar reservar(No compartir) una quota de sus recursos por un tiempo limitado.
| Cluster | Tipo de Usuario | Nombre de la Cola | Tiempo Maximo/Trabajo Wall Clock | CPU/Nodo | GPU/Nodo | RAM/Nodo | quota Asignada de Almacenamiento | quota Asignado para procesamiento | Prioridad de Recursos |
| Biocomputo | Asociados al CECC | cpu.normal.q | 15 dias o mas | de 8 a 16 | 0 | de 24Gb a 96 Gb | Quota Interna | Quota Interna | Alta |
| Miembro del CECC | cpu.cecc | hasta 8 dias | de 8 a 16 | 0 | de 24Gb a 96 Gb | 0Tb | Max. 2Tb | Baja | |
| Miembro del CECC | debug | Máximo 4 horas | de 8 a 16 | 0 | de 24Gb a 96 Gb | 0Tb | Max. 2Tb | Baja | |
| qteorica | Asociados al CECC | rack | hasta 8 dias | de 8 a 32 | 1 | hasta 62 Gb | Quota Interna | Quota Interna | Alta |
| Asociados al CECC | rack-gpu | hasta 8 dias | de 8 a 32 | 1 | hasta 62 Gb | Quota Interna | Quota Interna | Alta | |
| Miembro del CECC | cpu.cecc | hasta 8 dias | de 8 a 32 | 1 | hasta 62 Gb | 0Tb | Máx. 2Tb | Baja | |
| Miembro del CECC | gpu.cecc | hasta 8 dias | de 8 a 32 | 1 | hasta 62 Gb | 0Tb | Máx. 2Tb | Baja | |
| Miembro del CECC | debug | Máximo 4 horas | de 8 a 32 | 1 | hasta 62 Gb | 0Tb | Máx. 2Tb | Baja | |
| Fisica | Asociados al CECC | boltzman.cpu | hasta 8 dias | de 56 a 72 | 2 | 128Gb | Quota Interna | Quota Interna | Alta |
| Asociados al CECC | boltzmann.gpu | hasta 8 dias | de 56 a 72 | 2 | 128Gb | Quota Interna | Quota Interna | Alta | |
| Asociados al CECC | feynman.cpu | hasta 8 dias | de 56 a 72 | 0 | 128Gb | Quota Interna | Quota Interna | Alta | |
| Miembro del CECC | cpu.cecc | hasta 8 dias | de 56 a 72 | 2 | 128Gb | 0Tb | Máx. 2Tb | Baja | |
| Miembro del CECC | gpu.cecc | hasta 8 dias | de 56 a 72 | 2 | 128Gb | 0Tb | Máx. 2Tb | Baja | |
| Miembro del CECC | debug | Máximo 4 horas | de 56 a 72 | 2 | 128Gb | 0Tb | Máx. 2Tb | Baja | |
| CECC | Asociados al CECC | cpu.cecc | hasta 5 dias | de 64 a 128 | 0 | 512Gb | 0Tb | Máx. 2Tb | Alta |
| Miembro del CECC | cpu.cecc | hasta 3 dias | cd 8 a 64 | 0 | 256GB | 0Tb | Máx. 2Tb | Baja |
Referencias: https://hpc.llnl.gov,


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
arquitectura1.png | manage | 14 K | 10 Feb 2023 - 10:18 | AdminUser | arquitectura1.png |
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r15 < r14 < r13 < r12 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r15 - 16 Jun 2025, AdminUser
Ideas, requests, problems regarding Foswiki? Send feedback